📊📚 The State of the Art – Recent Research Highlights
To ground us a bit I want to start by summarizing some key research findings from the last 12 months.
The Good
Stanford Study - Predicting Expert Evaluations in Software Code Reviews

This study found lots of productivity gains for engineers in the workplace, but with a fair amount of nuance.
-
Complexity and Maturity: The largest gains (30-40%) were seen in low-complexity, greenfield tasks, while high-complexity, brownfield tasks showed the smallest gains (0-10%).
-
Language Popularity: AI was found to be less helpful for low-popularity languages and more effective for popular languages like Python (10-20% gains).
-
Codebase Size: As the codebase grows, the productivity gains from AI decrease significantly due to limitations in context windows and signal-to-noise ratio.
In conclusion, the study found that AI increases developer productivity by an average of 15-20%, but its effectiveness is highly dependent on the specific task, codebase, and language.
The Bad
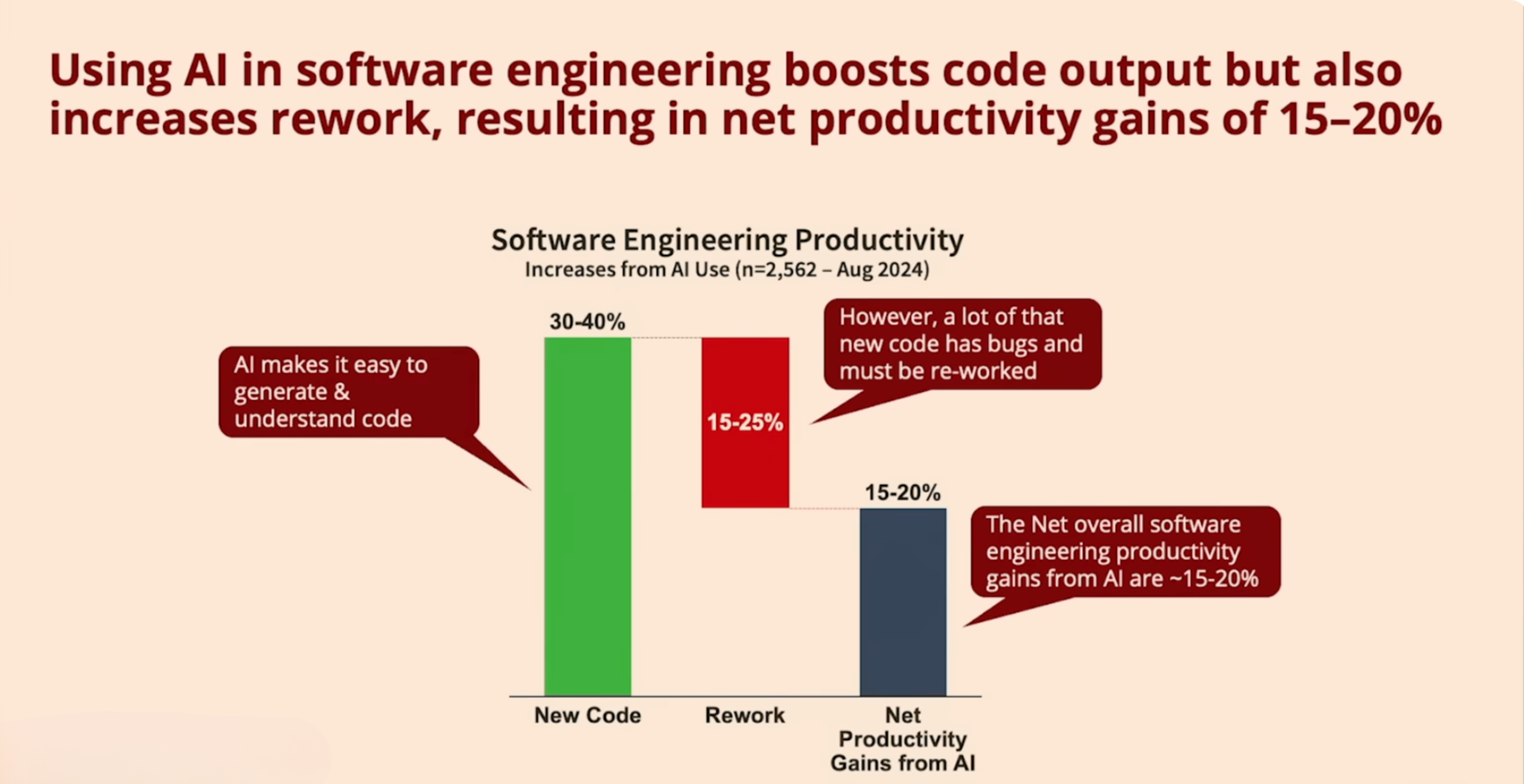
Continuing to reference the Stanford study above, we should also highlight that code created with LLM tools has some issues.
Along with the productivity gains described above there seems to be a lot of technical debt, or re-work, accumulated because of the use of these tools. So much so that it cuts the productivity gains in half. Even with this fiction, it still seems to be a net positive on productivity, but it’s something to keep in mind as we merge features to main.
See YouTube video by the lead author here.
UTSA - Importing Phantoms: Measuring LLM Package Hallucination Vulnerabilities
All tested models exhibited package hallucination, with rates between: 0.22% - 46.15%. This included packages that could potentially be security risks.
Organizations must carefully balance the trade-offs between model performance, security, and resource constraints when selecting models for code generation tasks.
The Ugly
NANDA - an MIT-led initiative - ROI Study
95% of enterprise generative AI pilot projects fail to deliver a meaningful ROI within 6 months.
Projects often stall in “pilot purgatory” because AI outputs are “confidently wrong,” requiring employees to spend extra time double-checking and correcting the results. This “verification tax” erases any potential ROI.
Using AI tools actually slowed down experienced open-source developers by ~ -20% on average, contrary to their own predictions (~ +20%).
The slowdown was attributed to developers spending more time reviewing AI outputs and prompting, due to AI’s unreliability and lack of implicit context in complex, familiar codebases.
The Takeaway
LLM based coding tools seem to add the most value when you are working with:
- type-ahead (where you can digest and verify each line more readily),
- a prototype,
- new feature,
- greenfield app,
- small to mid-size codebases, or
- more compact brownfield features
Beyond that they begin to have eroding value.
Sadly, these tools are not magic 🪄😞
If you are working with:
- highly ambiguous specs,
- a large, highly complex codebase, written in a low popularity language, or
- building generative features on your own bespoke model at your company
you should ask yourself: “Is using this tool going to make me more productive in this context?”
Still at the end of the day there seems to be clear boosts to productivity in many-many projects using these tools in the right contexts.